

Authored by Dr. Vijayalakshmi Saravanan, Assistant Professor in Computer Science at the University of South Dakota and promoter of diversity in the field of big data and computer science.
With over 300 million monthly active users, Twitter sees thousands of new accounts created daily. But how many of these new accounts are genuine, and how many are ephemeral users who quickly cease interactions with the platform? Adopting an innovative approach, we produced a dataset comprising over 500,000 new Twitter accounts created in April 2020. Identified immediately after registration, these accounts were closely monitored for 21 days, with a final status check conducted two years post-registration.
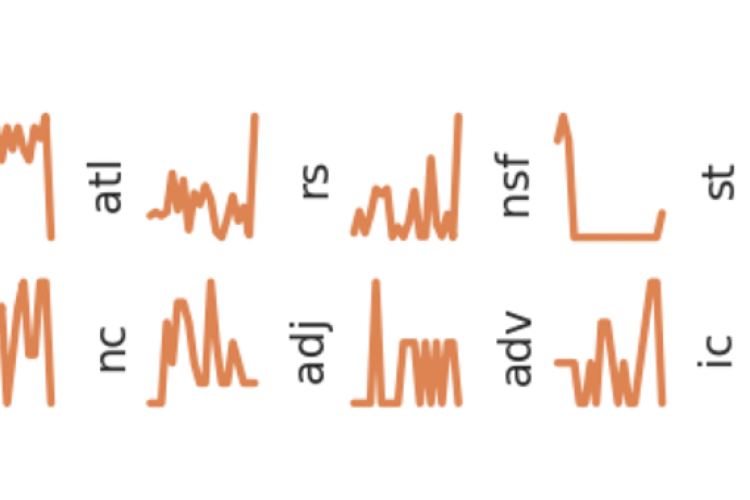
This article introduces the concept of integrating Time Series Analysis (TSA) with Natural Language Processing (NLP) to create a new representation, TOTS (Text tO Time Series). TOTS converts text data into time series, preserving the sequential structure of the text. The conversion process includes tokenization, feature extraction, and aggregation. The article explores various feature extraction techniques, such as linguistic features and sentence embeddings, and aggregation methods like average and max aggregation.
Social networks have become an integral part of our lives, connecting people and facilitating information sharing. However, the growing concerns of polarization and echo chambers within these platforms call for effective solutions. In the research paper "Rebalancing Social Feed to Minimize Polarization and Disagreement," scientists present an innovative algorithm that addresses this issue. By understanding the role of recommender systems and their impact on polarization, this algorithm offers a promising solution to foster more inclusive and constructive online environments.

Author: Leo Ferres, PhD Professor of Computer Science IDS UDD/Telefónica/ISI Foundation
As a computer science professor, I had the incredible opportunity to embark on a 7-week visit to the National Research Council (CNR) in Pisa.
I took the opportunity of the SoBigData++ Transnational Access to develop a collaboration with the CEU research unit directed by János Kertész in Vienna (Austria) on the program titled “Analysis of opinion dynamics over a realistic dynamic social network”. I was hosted for three weeks in the Department of Network and Data Science and worked closely with the unit. We ended up with very interesting results that we plan to summarize in a conference paper shortly.
Among the plethora of digital technologies emerging within the fourth industrial revolution, Industry 4.0 base Technologies (i.e., IoT, cloud services, big data, and analytics) have profoundly changed how companies produce goods and do business. Since the term Industry 4.0 was introduced in 2011, a massive amount of literature about how these technologies altered the companies’ business models has flourished in the last 12 years.

This article delves into Continual Learning (CL) and its intersection with Explainable AI (XAI). It introduces novel metrics to assess how explanations change as neural networks adapt to evolving data. Unlike traditional CL approaches, this study focuses on understanding the factors influencing explanation variations, such as data domain, model architecture, and CL strategy. Through the lens of SHapley Additive exPlanations (SHAP), the research benchmarks these factors across datasets and models, shedding light on explanation dynamics in CL scenarios.
A study conducted by the Institute of Information Science and Technologies (ISTI) of the National Research Council (CNR) has revealed new mechanisms for the formation of urban segregation through the analysis of human mobility within agent-based models. This research, which represents an important evolution of the models introduced by Nobel laureate in economics Thomas Schelling in 1971, offers a deeper perspective on the complexity of social and urban phenomena.