
Text to Time Series Representations: Towards Interpretable Predictive Models
This article introduces the concept of integrating Time Series Analysis (TSA) with Natural Language Processing (NLP) to create a new representation, TOTS (Text tO Time Series). TOTS converts text data into time series, preserving the sequential structure of the text. The conversion process includes tokenization, feature extraction, and aggregation. The article explores various feature extraction techniques, such as linguistic features and sentence embeddings, and aggregation methods like average and max aggregation. The resulting time series data can be paired with TSA techniques, such as shapelets, for improved interpretability in machine learning and AI.
In recent years, Natural Language Processing (NLP) and Time Series Analysis (TSA) have seen a significant surge in popularity. NLP is used in various areas like translation, spam detection, summarization, and question-answering. TSA identifies local patterns or components in time-dependent data, which have grown in availability in healthcare, IoT devices, environmental sciences, and finance. Combining NLP and TSA is relatively unexplored in the literature. Despite their distinct objectives, both fields deal with data represented as sequences, whether measurable values or words/sentences. Both traditional text encoding techniques and state-of-the-art text embedding models convert the textual data into a machine-readable input that represents the content as a whole without preserving the order of the contents. Still, from a human perspective, the text remains a sequence of spoken or written expressions rather than a comprehensive machine-readable representation.
In this work, we explore integrating TSA into NLP to improve interpretability in machine learning and AI through a type of representation that preserves the sequential structure of the text. To achieve this representation, we formalized the TOTS framework, which consists of turning Text tO Time Series. The conversion workflow covers three steps: tokenization, feature extraction, and aggregation.
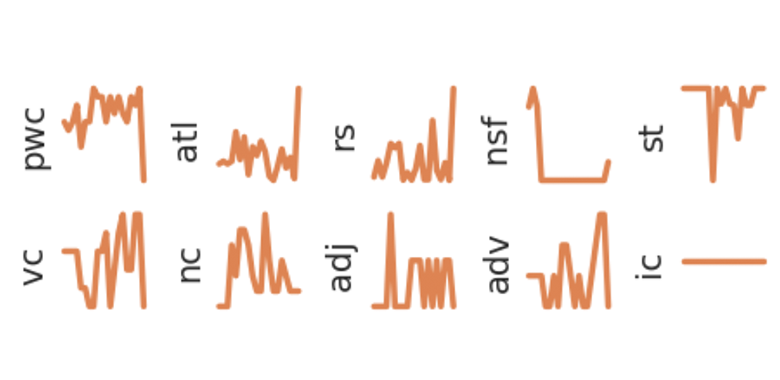
Tokenization involves breaking up a given text into units that can be individual words, phrases, or whole sentences. In the context of TOTS, tokenization determines the granularity of the final time series since tokens are the timesteps that sequentially compose time series. For example, here is an extract of a rap song split line by line from the SongLyrics dataset:

Feature extraction consists of using NLP techniques to convert each token into a vector representing characteristics of the text. In our experiments, we tested various feature extraction techniques, ranging from linguistic features, emotion/sentiment, and finally, more complex sentence embeddings obtained through transformers [2]. In this way, any text, in our example, a song, can be converted to a matrix that is essentially a multivariate time series representing the evolution of text according to the extracted features.
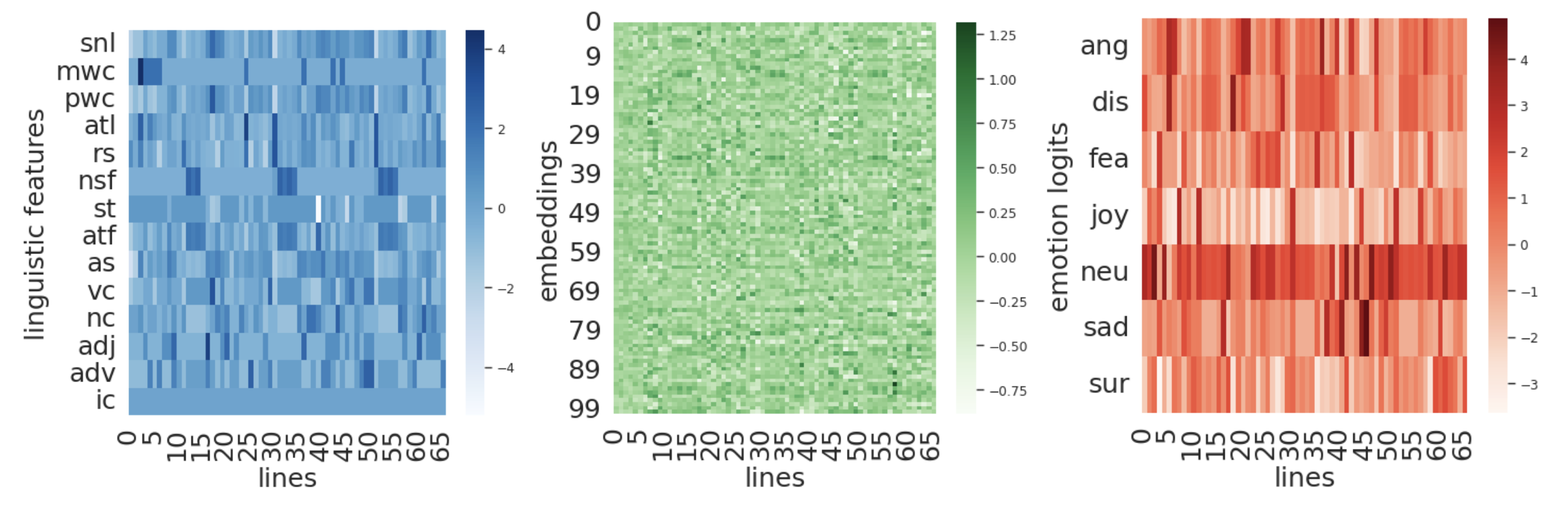
From left to right: multivariate time series obtained through feature extraction via (i) linguistic features, (ii) sentence embeddings, (iii) sentiment analysis.
Aggregation is the final step of reducing multivariate time series into univariate ones, using a function that takes a multivariate time series as input and "compresses" it into a univariate time series without changing the number of observations. This conversion simplifies the discovery patterns and regularities from the one signal composing the time series that can be easily relocated on both the multivariate time series and the original text, opening up further descriptive analysis. In this work, we experiment with average and max aggregation and with Principal Component Analysis (PCA)[3].
This text to time series conversion can be paired with any TSA technique. We used shapelets [4] with a simple decision tree to obtain a rule-based explanation based on subsequences for text classification. In our example, the decision tree relies on just two of the extracted subsequences (s1 and s14) to discern between the two musical genres by evaluating the distance (here denoted simply as "high" or "low") between the shapelets and the text conversion. Hence, there are only three rules to classify songs:
- if the distance between s14 and the converted text is low then the class is rap, else,
- if the distance with s1 is low then the class is pop, else,
- the class is rap.

Shapelet analysis approach on a linguistic time series aggregated with PCA.
From the comparison between the shapelet and the text, we can observe how the text evolves, in this case based on linguistic features. For instance, at the beginning of the shapelet, the normalized sentence frequency drops (nsf), indicating the end of the chorus and the beginning of the verse. A slight increase at the end highlights the beginning of a new chorus. Further, the alliteration score seems to grow in the verse, with the more rhythmic repetition of sounds (“To the little homies in the hood, claimin wards and wearin rags”). snl and pwc represent the higher length of sentences in the verse w.r.t. the chorus. Other subsequences are harder to interpret in this instance, such as the number of adjectives (adj) and verbs (vc).

Shapelet mapped to the original text.
As for quantitative experiments, we preliminary assessed the correctness of the conversion through an experiment based on time series similarity, on the premise that the TOTS framework would convert similar documents into similar time series. This first experiment allowed us to select combinations of feature extraction and aggregation methods that maximized the similarity between the text-generated time series and their augmented similar counterparts, as opposed to their random counterparts. We then proceeded to the main classification task, using three NLP datasets, comparing approaches based on univariate time series (such as shapelets), with classifiers trained on global and general statistics obtained from the relative multivariate ones. In general, shapelets and global features perform similarly; the advantage of using shapelets is to look at the importance of specific paragraphs in the text, which is impossible with global features.
For future works, we plan on exploring directly multivariate time series, without the aggregation step, and comparing TOTS against state-of-the-art NLP models and studying possible avenues of integration with Large Language Models. Finally, we plan on extending text shapelets' interpretability to unsupervised analyses, incorporating sequentiality in clustering or topic modeling.
REFERENCE
[1] Reimers, Nils, and Iryna Gurevych. "Sentence-bert: Sentence embeddings using siamese bert-networks." arXiv preprint arXiv:1908.10084 (2019).
[2] Ye, Lexiang, and Eamonn Keogh. "Time series shapelets: a new primitive for data mining." Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009.
[3] Maćkiewicz, Andrzej, and Waldemar Ratajczak. "Principal components analysis (PCA)." Computers & Geosciences 19.3 (1993): 303-342.